
Unsupervised Learning, auf Deutsch unüberwachtes Lernen, ist eine Kategorie des maschinellen Lernens. Es konzentriert sich auf die Analyse und Verarbeitung von Daten, ohne dass im Vorfeld Label oder Kategorien vorgegeben sind. Im Gegensatz zum Supervised Learning, das mit vorgegebenen Antworten arbeitet, um ein Modell zu trainieren, entdeckt Unsupervised Learning eigenständig Strukturen und Muster in den Daten. Diese Art des Lernens ist besonders nützlich, wenn Sie keine vorherigen Kenntnisse über die Daten haben oder wenn es zu kostspielig oder impraktikabel wäre, die Daten vorab zu kennzeichnen.
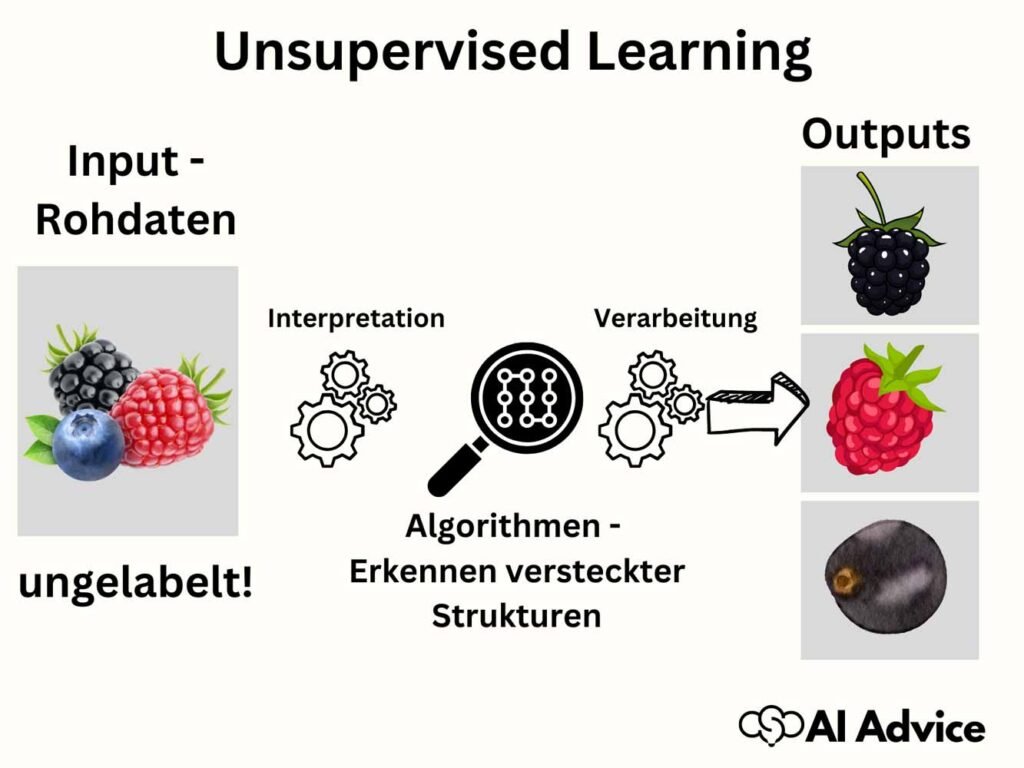
Bei Unsupervised Learning arbeiten Algorithmen daran, versteckte Muster oder Gruppierungen in den Daten zu erkennen. Dies erfolgt meist durch Methoden wie Clustering oder Assoziationsanalysen, die es ermöglichen, Datenpunkte auf Basis ihrer Ähnlichkeiten in Gruppen zu unterteilen oder Beziehungen zwischen verschiedenen Elementen aufzuzeigen. Diese Technologien sind in einer Vielzahl von Anwendungsfällen nützlich, von der Kundensegmentierung in der Wirtschaft bis hin zur Mustererkennung in der Datenwissenschaft.
Kernaussagen
- Unsupervised Learning ermöglicht es Algorithmen, ohne vorherige Beschriftung Muster in Daten zu finden.
- Es unterscheidet sich von Supervised Learning durch das Fehlen von vorgegebenen Antworten während des Trainings.
- Clustering ist eine häufig genutzte Methode im Rahmen von Unsupervised Learning, um Datenpunkte zu gruppieren.
Was ist eigentlich Unsupervised Learning?
Beim Unsupervised Learning, auch unüberwachtes Lernen genannt, geht es darum, Muster und Strukturen in unbeschrifteten Daten zu erkennen, ohne dass eine vorherige Anleitung gegeben wird. Diese Lernmethode ermöglicht es Algorithmen, eigenständig tiefergehende Einsichten aus Datensätzen zu gewinnen.
Unsupervised Learning versus Supervised Learning
Unsupervised Learning (unüberwachtes Lernen) unterscheidet sich vom Supervised Learning (überwachtes Lernen) hauptsächlich durch die Art der verwendeten Daten. Während Supervised Learning mit beschrifteten Daten arbeitet, bei denen Ein- und Ausgabewerte bekannt sind, nutzt Unsupervised Learning unbeschriftete Daten. Hier gibt es keine explizite Zielvariable. Der Fokus bei Unsupervised Learning liegt auf der Erkennung von Clustern oder der Dimensionsreduktion zur Auffindung von Strukturen innerhalb der Daten.
Die Grundlagen des unüberwachten Lernens
Die Grundidee des unüberwachten Lernens ist es, verborgene Muster und Zusammenhänge in Daten zu entdecken. Hierbei lernt ein Modell selbständig, indem es Datenpunkte zu Gruppen zusammenfasst oder die Komplexität von Daten durch Dimensionsreduktion verringert. Im Gegensatz zu überwachtem Lernen, gibt es beim Unsupervised Learning keine vordefinierten Labels, was die Algorithmen vor die Herausforderung stellt, ohne überwachte Anleitung auszukommen.
Wo Unsupervised Learning in die Welt der Künstlichen Intelligenz passt
Unsupervised Learning ist eine zentrale Komponente in der Welt der Künstlichen Intelligenz (KI). Es spielt eine bedeutende Rolle im Deep Learning und Neuralen Netzwerken, da es dabei hilft, komplexe Daten ohne menschliches Eingreifen zu analysieren. Anwendungen finden sich in Bereichen wie Data Mining, wo es darum geht, umfangreiche Informationssätze selbstständig zu durchforsten und zu strukturieren. Unsupervised Learning ist daher ein mächtiges Werkzeug, um Einsichten in große und komplexe Datensätze zu erlangen, wo menschliche Fähigkeiten an ihre Grenzen stoßen.
Wie funktioniert Unsupervised Learning?

Unsupervised Learning, ein Kernzweig des maschinellen Lernens, konzentriert sich darauf, Muster und Zusammenhänge in Daten zu erkennen, ohne dass diese explizit markiert oder etikettiert sind.
Einblicke in die Algorithmen des unüberwachten Lernens
Unüberwachte Lernalgorithmen verstehen Daten, ohne auf vordefinierte Labels angewiesen zu sein. Stattdessen identifizieren sie eigenständig Regelhaftigkeiten und Muster in den Eingabevariablen. Dabei sind Clustering und Dimensionalitätsreduktion die verbreitetsten Techniken. Clustering-Algorithmen wie k-Means Clustering oder hierarchisches Clustering teilen die Daten in Gruppen ein, wobei Datenpunkte innerhalb einer Gruppe ähnlich und zwischen verschiedenen Gruppen unähnlich sind.
Anwendungsbeispiele von Unsupervised Learning
Die Anwendungen von Unsupervised Learning sind vielseitig und umfassen Marktbasket-Analyse, Anomalieerkennung, Clusteranalyse und Empfehlungssysteme. Diese Methoden ermöglichen die Exploration von Datensätzen, um verborgene Muster zu entdecken, die für Vorhersagen oder Entscheidungsfindungen nützlich sein können.
Clustering und Dimensionalitätsreduktion erklärt
Beim Clustering werden Datensätze in natürliche Gruppierungen aufgeteilt. k-Means Clustering ist ein gängiger Algorithmus, bei dem k Gruppen gebildet werden. Hierarchische Clustering erstellt eine Baumstruktur von Clustern. Dimensionalitätsreduktion, wie z.B. die Hauptkomponentenanalyse (PCA) oder Singulärwertzerlegung, verringert die Anzahl der Variablen in einem Datensatz, wobei diejenigen, die die meiste Variabilität in den Daten tragen, beibehalten werden. Autoencoder werden ebenfalls für diese Aufgabe genutzt, indem sie die Daten auf eine niedrigdimensionale Repräsentation komprimieren.
Die wichtigsten Anwendungsbereiche von Unsupervised Learning
Unsupervised Learning spielt eine entscheidende Rolle in der Analyse von großen Datensätzen. Es hilft Ihnen, Muster zu erkennen, Anomalien zu identifizieren, und ermöglicht eine effiziente Datengruppierung ohne vorherige Annotierung der Daten.

Erkennung von Anomalien in Datensätzen
Im Bereich Anomalieerkennung bei Data Science ermöglicht Unsupervised Learning Ihnen, Ausreißer und ungewöhnliche Muster in Ihren Daten zu identifizieren. Dies ist vor allem relevant, um Betrug, Systemfehler oder unerwünschte Abweichungen in Echtzeit zu entdecken. Da kein vorheriges Labeling erforderlich ist, können Sie mittels Unsupervised Learning schnell und effizient Anomalien in großen Datensätzen erkennen.
Clusteranalyse zur Gruppierung von Datenpunkten
Unsupervised Learning wird häufig für die Clusteranalyse genutzt, um Datenpunkte in Gruppen zu segmentieren. Dabei werden ähnliche Objekte basierend auf ihren Merkmalen in einem Datensatz zusammengefasst. Dies ist besonders nützlich in Bereichen wie Marktsegmentierung, Genetik und Organisation von Big Data. Durch Clustering können Sie natürliche Strukturen in Ihren Daten erkennen und Gruppen identifizieren, was zu wertvollen Einblicken in Ihre Daten führt.
Wie Unsupervised Learning in Datenanalyse und Vorhersagen eingesetzt wird
Darüber hinaus spielt Unsupervised Learning eine wesentliche Rolle in der Datenanalyse und bei Vorhersagen. Es kann verwendet werden, um Wahrscheinlichkeiten zu modellieren, Zusammenhänge in Daten aufzuspüren und letztlich Prognosen zu erstellen. Obwohl es keine definitiven Antworten liefert, kann Unsupervised Learning helfen, Hypothesen für weiterführende Untersuchungen aufzustellen und Trends in Daten zu erkunden, was für die Vorhersage von Markttrends oder Kundenverhalten von Bedeutung sein kann.
Clustering: Ein tiefer Einblick in eine zentrale Methode des Unsupervised Learning
Clustering ist ein wesentliches Verfahren im Unsupervised Learning, das Ihnen hilft, Einsichten aus ungelabelten Daten zu gewinnen. In diesem Kontext betrachten wir seine Funktionsweise, verschiedene Methoden und praktische Anwendungsfälle.
Wie Clustering funktioniert und wann es eingesetzt wird
Clustering ermöglicht die Gruppierung von Datenpunkten in relevante Untergruppen, sogenannte Cluster, basierend auf Ähnlichkeiten, ohne dass vorherige Etiketten vorhanden sein müssen. Idealerweise sollten Objekte innerhalb eines Clusters eine hohe Ähnlichkeit haben, während sie sich von Objekten anderer Cluster unterscheiden. Unsupervised Learning kommt zum Einsatz, wenn Sie es mit einer großen Menge an Daten konfrontiert sind, die keine vordefinierten Kategorien oder Gruppen haben. Zum Beispiel werden Algorithmen fürs Clustering eingesetzt, um Kundenverhalten zu analysieren oder im Data Mining, um verborgene Muster in Daten zu identifizieren.
Die Unterschiede zwischen den Clustering-Methoden
Es gibt verschiedene Clustering-Methoden, die sich in ihrem Ansatz und ihrer Komplexität unterscheiden. Zwei prominente Methoden sind:
- K-Means Clustering: Hier geben Sie die Anzahl der Cluster vor, und der Algorithmus ordnet die Punkte durch Minimierung der Varianz innerhalb der Cluster zu. K-Means Clustering ist ideal für große Datensätze.
- Hierarchisches Clustering: Dieser Algorithmus bildet eine Hierarchie von Clustern, die als Baumdiagramm, genannt Dendrogramm, visualisiert wird. Hierarchisches Clustering ist nützlich, wenn die Beziehung zwischen den Datenpunkten verstanden werden soll.
In einer vergleichenden Tabelle könnte man zum Beispiel folgende Kernpunkte für die Methoden festhalten:
| Methode | Beschreibung | Einsatzgebiet |
|---|---|---|
| K-Means Clustering | Gruppenbildung durch vorab bestimmte Clusteranzahl, effizient bei großen Datenmengen. | Marktsegmentierung, Kundencluster |
| Hierarchisches Clustering | Bildet eine Hierarchie von Clustern, visualisiert in einem Dendrogramm. | Genomanalyse, soziale Netzwerke |
Praktische Anwendungsfälle für Clustering im realen Szenario
Clustering kann in vielfältigen Domänen zur Identifizierung von Mustern und Strukturen angewendet werden. Einige Anwendungsfälle umfassen:
- Marktsegmentierung: Unterteilung von Kunden in Gruppen basierend auf Kaufverhalten oder Präferenzen.
- Soziale Netzwerke: Erkennung von Gemeinschaften innerhalb von Netzwerken, basierend auf den Interaktionen und Verbindungen der Nutzer.
- Biowissenschaften: Gruppierung von Genen oder Proteinen mit ähnlichen Funktionsmerkmalen.
Diese Anwendungsfälle zeigen, dass Clustering es Ihnen ermöglicht, verschleierte Informationen in unaufbereiteten Daten zu entdecken und zu nutzen, um maßgeschneiderte Strategien in Ihrem Anwendungsbereich zu entwickeln.
Unüberwachtes Lernen: Vor- und Nachteile
Unüberwachtes Lernen, ein zentraler Zweig des maschinellen Lernens, zeichnet sich durch die Fähigkeit aus, Muster in unbeschrifteten Daten zu erkennen. Allerdings bietet es auch Herausforderungen, die spezifische Anwendungen und Kontexte erfordern.
Die Stärken des unüberwachten Lernens
- Entdeckung von Mustern: Unsupervised Learning eignet sich besonders für die Erkundung von Big Data, um versteckte Strukturen oder Muster zu entdecken, ohne dass eine vorherige Kennzeichnung der Daten erforderlich ist.
- Dimensionalitätsreduktion: Durch Verfahren wie PCA (Principal Component Analysis) kann die Dimensionalität der Daten reduziert werden. Dies führt zu einer effizienteren Verarbeitung und Visualisierung und verringert die Komplexität.
Herausforderungen und Grenzen des Unsupervised Learning
- Komplexität und Interpretation: Die Algorithmen können komplex sein, und Sie können die ermittelten Ergebnisse nicht immer eindeutig oder einfach interpretieren.
- Begrenzte Anwendbarkeit: Es gibt Szenarien, in denen die Spezifität und Genauigkeit supervisionierten oder semi-supervisionierten Ansätze vorzuziehen sind. Das gilt insbesondere, wenn hochpräzise Vorhersagen erforderlich sind.
Wann sollte Unsupervised Learning anderen Lernmethoden vorgezogen werden?
- Datenverfügbarkeit: Wenn Sie keinen Zugang zu klassifizierten oder beschrifteten Daten haben, bietet sich Unsupervised Learning als Methode an, um dennoch Einblicke zu gewinnen.
- Spezifität der Anwendung: In Fällen, wo es mehr um die Mustererkennung als um die Vorhersagegenauigkeit geht, wie zum Beispiel bei der Kundensegmentierung, können unüberwachte Lernmethoden optimal sein.
Die Zukunft von Unsupervised Learning im Machine Learning

Die fortschreitende Entwicklung im Bereich von Unsupervised Learning trägt maßgeblich zu bedeutenden Durchbrüchen in der Analytik von umfangreichen Datensätzen bei. Sie stehen im Zentrum zukünftiger Innovationen im Machine Learning.
Innovationen und Entwicklungen im Bereich des unüberwachten Lernens
In Ihrem beruflichen Umfeld könnten Sie bald feststellen, dass Machine Learning Modelle, basierend auf unüberwachtem Lernen, komplexe Muster und Beziehungen in Daten erkennen, ohne auf vorher festgelegte Kategorien angewiesen zu sein. Zukunftsträchtige Innovationen wie neue Arten von Autoencodern und fortschrittliche neuronale Netze beabsichtigen, eine noch präzisere Analyse unstrukturierter Daten durchzuführen. Deep Learning-Techniken, die ohne menschliche Aufsicht auskommen, könnten effizientere und selbstständigere Systeme hervorbringen.
Die Rolle von Unsupervised Learning in der Verarbeitung von großen Datenmengen
Big Data ist ein zentraler Faktor für den Einsatz von Unsupervised Learning. Die Fähigkeit, aus großen, unstrukturierten Datenmengen sinnvolle Informationen zu extrahieren, ist für Ihr Unternehmen von großem Wert. Intuitive Machine Learning Algorithmen sind in der Lage, verborgene Muster zu erkennen, was wiederum zu einer effektiveren und schnelleren Datenanalyse führt. Dieser Ansatz kann insbesondere dort eingesetzt werden, wo das manuelle Labeln von Daten nicht umsetzbar ist.
Interdisziplinäre Anwendungsbereiche und das Potenzial von Unsupervised Learning
Unsupervised Learning findet in vielen Branchen Anwendung, was Ihre beruflichen Möglichkeiten erweitert. In der Biotechnologie könnten neuronale Netzwerke dabei helfen, genetische Muster zu identifizieren. Im Finanzwesen können Sie Anomalien und Betrugsfälle aufdecken. Auch im Marketing lassen sich Konsumentengruppen genau segmentieren und Verhaltensmuster erkennen. Diese interdisziplinären Anwendungen zeigen das enorme Potenzial von Unsupervised Learning und veranschaulichen dessen Einfluss auf die Zukunft von Machine Learning.