
Supervised Learning ist ein zentraler Begriff im Bereich des maschinellen Lernens und ein fundamental wichtiges Konzept im Rahmen der künstlichen Intelligenz. Es beschreibt den Prozess, bei dem ein Algorithmus aus einem Datensatz mit bekannten Ergebnissen – den sogenannten Trainingssamples – lernt. Diese Lernmethode ermöglicht es, präzise Vorhersagen zu machen oder Daten in Kategorien einzuteilen, indem sie Muster in eines Datensatzes erkennt und nachvollzieht.
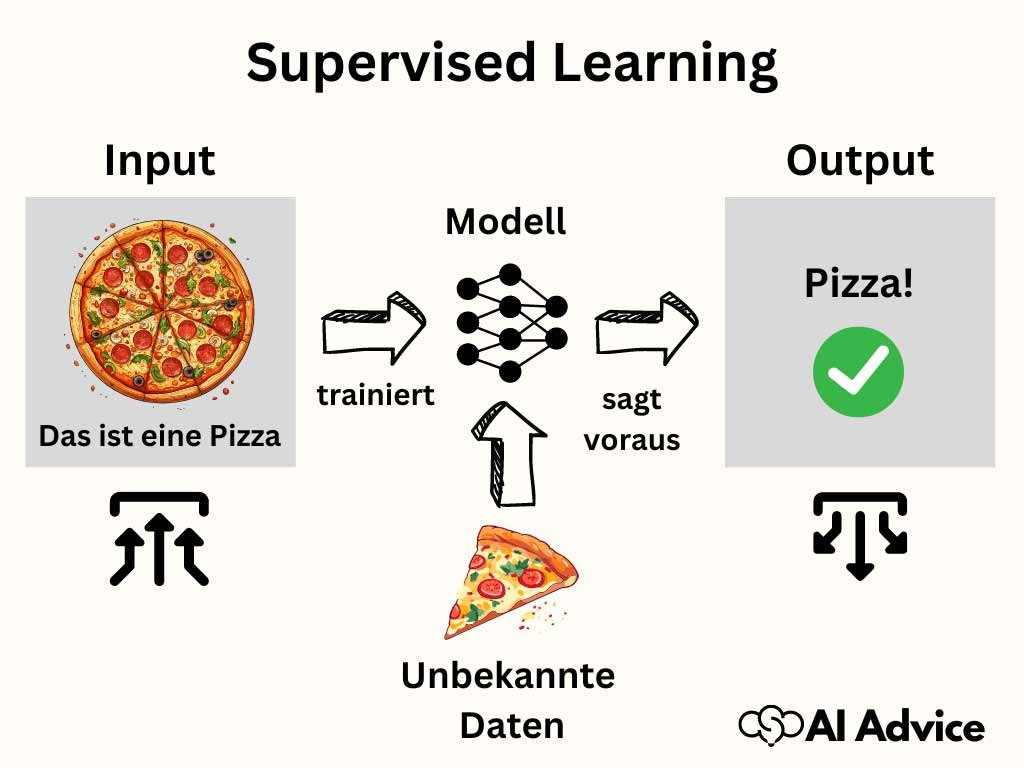
Beim Supervised Learning wird der algorithmische Modellansatz trainiert, indem ihm Beispiele vorgelegt werden, die sowohl die Eingabedaten als auch die gewünschten Ausgabewerte enthalten. Die Algorithmen verwenden diese Trainingsbeispiele, um zu lernen und die Beziehung zwischen den Eingangsdaten und den Ergebnissen zu verstehen. Nach abgeschlossenem Training kann das Modell neue, unbekannte Daten analysieren und prädiktive Ergebnisse oder Klassifikationen liefern. Dieser Prozess ist entscheidend für zahlreiche Anwendungen der künstlichen Intelligenz, wie beispielsweise das Erkennen von Handschrift, die Spracherkennung oder die Empfehlungssysteme in Online-Shops.
Kernaussagen
- Supervised Learning ermöglicht es Maschinen, Vorhersagen und Klassifikationen durch Trainingsdaten zu lernen.
- Diese Methode ist fundamental in der künstlichen Intelligenz und bei maschinellen Lernalgorithmen.
- Es findet breite Anwendung in verschiedenen Bereichen wie Sprach- und Bilderkennung.
Was ist Supervised Learning?
Supervised Learning, oder überwachtes Lernen, ist eine zentrale Methode in der Künstlichen Intelligenz (KI), die es Computern ermöglicht, aus Erfahrung zu lernen und präzise Vorhersagen zu treffen.
Definition von Supervised Learning in der KI
Beim Supervised Learning trainieren Sie ein Modell mit einem Satz von Daten, die bereits Labels besitzen. Diese Labels repräsentieren die korrekten Antworten für die eingegebenen Daten. Das Ziel ist es, dass das Modell Muster und Beziehungen in diesen Daten erkennt und lernt, auf neue, unbezeichnete Daten die richtigen Vorhersagen zu übertragen.
Grundprinzipien beim Supervised Learning
Die Grundprinzipien beim Supervised Learning umfassen die Nutzung von labeled data, um Muster innerhalb der Daten zu erkennen. Dabei wird zwischen Klassifikation und Regression unterschieden:
- Klassifikation: Bei dieser Aufgabe wird vorhergesagt, zu welcher Kategorie eine neue Beobachtung gehört. Typisches Beispiel wäre die E-Mail-Spam-Erkennung.
- Regression: Hier wird ein kontinuierlicher Wert vorhergesagt, wie zum Beispiel der Preis eines Hauses basierend auf verschiedenen Merkmalen.
Unterschiede zwischen Supervised Learning, Unsupervised Learning und Reinforcement Learning
- Supervised Learning ist dadurch gekennzeichnet, dass es sich auf vorher gelabelte Daten stützt.
- Unsupervised Learning, oder unüberwachtes Lernen, arbeitet mit unlabeled data und versucht, darin Muster ohne vorherige Kennzeichnung zu finden.
- Reinforcement Learning unterscheidet sich dadurch, dass hier ein Agent durch Belohnungen lernt, welche Aktionen in verschiedenen Situationen die besten Ergebnisse liefern.
Hier ist eine Tabelle, die die wichtigsten Unterschiede zwischen Supervised Learning, Unsupervised Learning und Reinforcement Learning zusammenfasst:
| Kriterium | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Eingabedaten | Gelabelte Daten mit bekannten Ausgabewerten | Ungelabelte Daten ohne bekannte Ausgabewerte | Keine vordefinierten Daten |
| Ziel | Vorhersage von Ausgabewerten für neue Eingabedaten | Entdecken von Mustern und Strukturen in den Daten | Lernen durch Interaktion mit der Umgebung, um Belohnungen zu maximieren |
| Problemtypen | Regression und Klassifikation | Clustering und Assoziationsanalyse | Entscheidungsfindung, Kontrolle, Spielen |
| Überwachung | Starke Überwachung durch gelabelte Trainingsdaten | Keine Überwachung, selbstständiges Lernen | Teilweise Überwachung durch Belohnungsfunktion |
| Algorithmen | Lineare Regression, Logistische Regression, Entscheidungsbäume, Neuronale Netze | K-Means, DBSCAN, Hierarchisches Clustering | Q-Learning, SARSA, Deep Q Networks |
| Anwendungen | Bildklassifizierung, Spracherkennung, Preisprognose | Kundensegmentierung, Anomalieerkennung, Empfehlungssysteme | Robotersteuerung, autonomes Fahren, Spielen |
Semi-Supervised Learning fällt zwischen supervised und unsupervised Learning, wobei es sich um eine Mischung aus gelabelten und unglabelten Daten handelt, um ein effektiveres Lernmodell zu entwickeln.
Wie funktioniert Supervised Learning?
In Supervised Learning verwendet Ihr Algorithmus eindeutig markierte Daten, um Vorhersagen oder Klassifizierungen zu lernen und durchzuführen. Ihr Trainingsdatensatz besteht aus Eingaben (Inputs) und den zugehörigen Ausgaben (Outputs), und der Algorithmus entwickelt ein Modell, das diese Verbindungen abbildet.
Der Lernprozess und die Nutzung von Trainingsdatensätzen
Ihre Modelle lernen mithilfe eines Trainingsdatensatzes, der aus Eingabewerten (Inputs) besteht, die gekennzeichnete Ausgabewerte (Outputs) haben. Diese Datensätze werden zur „Schulung“ des Modells verwendet, um Muster und Beziehungen zu erkennen. Das Ziel ist es, dass das Modell nach Abschluss des Trainings mit neuen, unbekannten Daten effektiv arbeiten kann. Dabei wird die Genauigkeit der Prediktion (Vorhersage) auf Grundlage der erlernten Daten bewertet.
Beispiele für Algorithmen im Supervised Learning
Es gibt eine Vielzahl an Algorithmen:
- Klassifikationsalgorithmen, wie zum Beispiel der k-Nearest Neighbors (kNN) Algorithmus, dienen dazu, Daten einem bestimmten Label zuzuweisen.
- Regressionsmodelle, wie lineare Regression oder polynomiale Regression, werden verwendet, wenn Ihre Ausgabe eine kontinuierliche Variable ist.
Automatisieren von Klassifikation und Regression mit Supervised Learning
Supervised Learning kann das Automatisieren von Prozessen im Bereich der Klassifikation und Regression enorm vereinfachen. Systeme können selbstständig lernen, ob eine E-Mail Spam ist (Klassifikation) oder den Preis einer Immobilie vorhersagen (Regression). Ihre Aufgabe besteht darin, das Modell mit umfangreichen und gut markierten Trainingsdaten zu versorgen, damit es effektive Vorhersagen treffen kann.
Vor- und Nachteile von Supervised Learning
Überwachtes Lernen, bildet die Grundlage für viele Anwendungen im Bereich des maschinellen Lernens. Ihre Entscheidung für oder gegen Supervised Learning hängt von verschiedenen Faktoren ab, darunter die Präzision der Prognosen, die Komplexität der Datenverarbeitung und das Gleichgewicht zwischen Verzerrung (Bias) und Varianz.
Das Maximieren der Genauigkeit von Prognosen
Supervised Learning zeichnet sich durch seine hohe Genauigkeit bei der Vorhersage von Ergebnissen aus. Diese Methode des maschinellen Lernens basiert auf annotierten Datensätzen, die ein Modell durch die Zuordnung von Eingabedaten zu bekannten Ausgaben trainieren. Dies ermöglicht es, präzise Vorhersagen und Klassifizierungen für ähnliche Datensätze zu treffen.
| Vorteile | Nachteile |
|---|---|
| Präzise Vorhersagen und Klassifikationen möglich, wenn ausreichend Trainingsdaten vorhanden sind | Aufwändige Datenaufbereitung und Annotation der Trainingsdaten nötig |
| Viele verschiedene Problemstellungen können bearbeitet werden, z.B. Bild- und Spracherkennung, Betrugserkennung, Preisprognosen | Begrenzt auf die gelernten Muster und Zusammenhänge, keine Kreativität oder Anpassungsfähigkeit |
| Einfacher zu verstehen und umzusetzen als andere Ansätze wie Unsupervised oder Reinforcement Learning | Kann nicht mit unbekannten oder unvorhergesehenen Daten umgehen |
| Ergebnisse und Ziele sind klar definiert und überprüfbar | Neigt zu Overfitting, wenn Modell zu stark an Trainingsdaten angepasst ist |
| Einmal trainiertes Modell kann Vorhersagen schnell und effizient treffen, ohne weiteres Training | Funktioniert nicht für Aufgaben, bei denen die Zielvariablen nicht bekannt oder definiert sind |
Herausforderungen beim Überwachten Lernen
Trotz seiner Vorteile hat überwachtes Lernen auch einige Herausforderungen. Eine davon ist das Risiko des Overfitting, wenn das Modell zu komplex ist und zu genau an den Trainingsdaten haftet. Dies führt dazu, dass es auf neuen, unbekannten Datensätzen unterdurchschnittlich abschneidet. Zudem können die Limitationen des überwachten Lernensin der Zeit und den Ressourcen liegen, die für die Sammlung und Annotation von Daten aufgewendet werden müssen.
Balancing zwischen Bias und Variance
Ein kritischer Aspekt ist das Finden des richtigen Gleichgewichts zwischen Bias und Variance. Ein hoher Bias kann zu einer Unterschätzung von komplizierten Zusammenhängen im Modell führen (Underfitting), während eine hohe Variance das Modell zu anfällig für Fluktuationen in den Trainingsdaten macht (Overfitting). Das Ziel ist, ein Modell zu entwickeln, das generalisierbar bleibt und gut auf neue Daten übertragen werden kann.
Wichtige Algorithmen und Methoden im Supervised Learning

Im Bereich des Supervised Learning verwenden Sie eine Vielzahl an Algorithmen und Methoden, um präzise Prognosen anhand Ihrer Daten zu erstellen. Die Wahl des Algorithmus hängt stark von der Art der Daten und der zu lösenden Aufgabe ab.
Lineare Regression und logistische Regression erklärt
Lineare Regression ist einer der einfachsten Algorithmen im überwachten Lernen. Sie ermöglicht Ihnen die Vorhersage eines kontinuierlichen Wertes, wie zum Beispiel Preise oder Temperaturen. Das Modell nimmt an, dass zwischen den unabhängigen Variablen (den Features) und der abhängigen Variable (Ihrem Zielwert) ein linearer Zusammenhang besteht.
Im Gegensatz dazu ist logistische Regression nützlich für binäre Klassifikationsprobleme – dort, wo Ihre Ergebnisse zwei Zustände annehmen können, wie ‚Ja‘ oder ‚Nein‘. Dieser Algorithmus schätzt die Wahrscheinlichkeit, dass eine Beobachtung zu einer bestimmten Klasse gehört, indem eine logistische Funktion verwendet wird.
Klassifikation mit Support Vector Machines (SVM)
Support Vector Machines (SVM) sind komplexe Klassifikationsalgorithmen, die besonders gut bei kleineren Datensätzen mit vielen Features funktionieren. SVM zielen darauf ab, eine Entscheidungsgrenze zu finden, die die Klassen von Datenpunkten mit maximalem Abstand trennt. Diese Methode ist bekannt für ihre Robustheit, besonders in Fällen, wo die Klassentrennung nicht klar ist.
Deep Learning als Erweiterung des supervised machine learning
Deep Learning bezieht sich auf komplexe Netzwerke, die aus vielen Schichten bestehen – die so genannten neuronale Netzwerke. Diese simulieren die Informationsverarbeitung des menschlichen Gehirns und sind in der Lage, Muster und Beziehungen in großen Datenmengen zu erkennen. Deep Learning erweitert das Feld des überwachten Lernens, indem es Aufgaben wie Bild- und Spracherkennung ermöglicht, die mit traditionellen Algorithmen schwer zu bewältigen sind.
In Python können Sie Bibliotheken wie Keras oder TensorFlow nutzen, um auf einfache Weise mit Deep Learning-Modellen zu arbeiten. Sie stellen Werkzeuge zur Verfügung, mit denen Sie neuronale Netzwerke effizient trainieren und anpassen können.
Anwendungsbeispiele und Einsatzgebiete von Supervised Learning
Supervised Learning ermöglicht es Ihnen, Muster zu erkennen und Vorhersagen auf Basis von historischen Daten zu treffen. Diese Methode des maschinellen Lernens findet in vielen verschiedenen Bereichen Anwendung, wo sie wichtige Funktionen übernimmt.
Spam-Erkennung in E-Mails
Durch Supervised Learning können Ihre E-Mail-Systeme mithilfe von Spam-Detektion unerwünschte Nachrichten filtern. Ein Algorithmus lernt aus einer Menge von E-Mails, die als Spam markiert sind, und verbessert kontinuierlich seine Fähigkeit, solche Nachrichten zu erkennen und entsprechend zu klassifizieren.
Vorhersage von Kundenverhalten und Marktanalysen
Prädiktive Analysen helfen Ihnen, Kaufentscheidungen Ihrer Kunden zu verstehen und vorherzusagen. Supervised Learning-Algorithmen analysieren historische Kaufdaten und Kundenfeedback, um Muster im Kundenverhalten zu identifizieren. Dadurch können Sie Marktanalysen ausführen und Kundensentimentanalysen zur Optimierung von Marketingstrategien nutzen.
Verbesserung der Fahrzeugsteuerung in der autonomen Fahrzeugtechnologie
In der Technologie autonomer Fahrzeuge spielt überwachtes Lernen eine zentrale Rolle. Algorithmen, die mit einer Vielzahl von Fahrsituationen und Reaktionen trainiert werden, ermöglichen es Fahrzeugen, aus Bilddaten zu lernen und komplexe Fahraufgaben wie das Erkennen von Verkehrszeichen oder Fußgängern zu bewältigen. Ihre Nutzung trägt zur Entwicklung sichererer und effizienterer autonomer Fahrzeuge bei.
Semi-Supervised Learning und seine Rolle im Kontext von Supervised Learning
Semi-Supervised Learning bildet eine Schlüsselkomponente im Maschinenlernen, indem es die Merkmale von Supervised und Unsupervised Learning kombiniert, um effektivere Modelle zu trainieren.
Verbindung zwischen supervised und unsupervised learning
Sie sind bereits mit Supervised Learning vertraut, wo Modelle mit gelabelten Daten trainiert werden, um Vorhersagen oder Klassifizierungen durchzuführen. Dagegen nutzt Unsupervised Learning ungelabelte Daten, um Muster oder Zusammenhänge in den Daten zu identifizieren, oft durch Verfahren wie Clustering. Semi-Supervised Learning verknüpft diese beiden Ansätze, indem es eine Kombination aus gelabelten und ungelabelten Daten für den Trainingsprozess verwendet.
Wie semi-supervised learning die Lücke schließt
Der Lernprozess in Semi-Supervised Learning nutzt eine kleine Menge gelabelter Daten zusammen mit einem größeren Pool von ungelabelten Daten, um die Leistung von maschinellen Lernmodellen zu verbessern. Dies ist besonders nützlich, wenn die Etikettierung von Daten aufwendig oder teuer ist. Semi-Supervised Learning verwendet die vorhandenen gelabelten Daten für eine anfängliche Führung und lernt dann aus den ungelabelten Daten dazu, um die Modellgenauigkeit während des Validierungsprozesses zu erhöhen.
Praktische Anwendungsbeispiele für semi-supervised learning
In der Praxis sehen Sie Semi-Supervised Learning in Bereichen wie Datenmining und Textklassifizierung, wo eine umfangreiche Datenetikettierung oft nicht realisierbar ist. Zum Beispiel kann ein Unternehmen eine Maschine mit einer begrenzten Menge an gelabelten Kundenbewertungen trainieren und das Modell dann auf eine größere Menge an ungelabelten Bewertungen anwenden, um Stimmungen oder Feedback-Kategorien zu identifizieren. Dies führt zu einer effizienteren Nutzung des Trainingsdaten, wo die gelabelten Daten den ungelabelten Kontext verstärken und umgekehrt.